


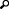
- Contents
Virtualization Technical Reference
Hyper-V Live Migration and VMware VMotion
Redundancy is built into the full suite of PureConnect products. The fact that redundancy is already available gives the PureConnect software application layer awareness.
For a standard CIC server pair running with a Primary and a Backup, the application state is not replicated, nor would it be desirable. Problems such as memory corruption, viruses, or application faults would be replicated as well.
In the diagram below, the Primary Server (IC1) is a guest virtual machine on Host A and the Backup Server (IC2) is a guest virtual machine on Host B.
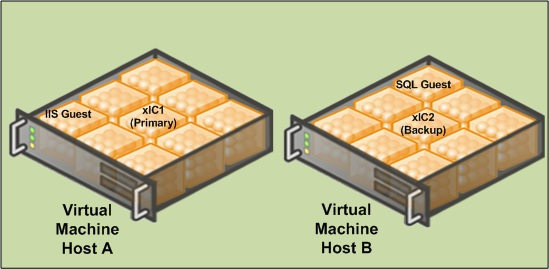
If Power is lost to Host A, the VM software detects the failure and tries to restore the servers running on Host A.In the meantime, the server on Host B has taken over the call processing. The state information is lost just as it would be with a real server.
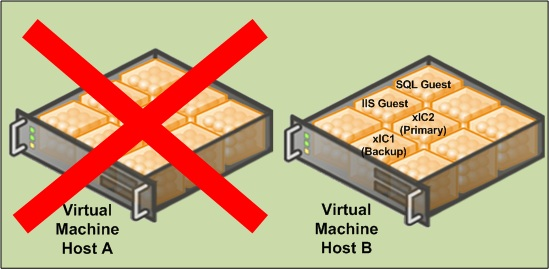
It is not recommended to move VMs handling load in production. In lab testing, the timing can be sensitive on machines handling multiple interactions per second. Some real-time data can be potentially lost. It is for this reason that-in a VMware environment - we strongly recommend assigning VMotion traffic to a dedicated NIC.Live Migration traffic should also run on a separate NIC away from the guests and management traffic.
It is a best practice to run redundant PureConnect products on separate physical hosts to take advantage of the hardware redundancy they afford. If a host restarts (even in a clustered environment), all guests on that host are restarted. Running similar guests on the same host does not provide the flexibility for services driver updates and software updates to a host.
Important!
Test your resiliency strategy before going into production. Ensure that
the guests can fail from different hosts in the cluster without causing
a licensing issue.
VMware High Availability is a feature that provides multiple hosts in a cluster with the capability to recognize when a vSphere host failure has occurred and to respond to the resultant failure of guest virtual machines. Any guest virtual machines that were on the failed host are powered off (like a power failure on physical servers).This may be fine for redundant services like Off-Host Session Manager, but an unscheduled restart of a CIC server during business hours is typically unacceptable. To mitigate this risk present in any virtualization platform, we recommend the use of Switchover systems to maintain the best fault tolerance available.
Many times an administrator does not know what host is running a guest in a large VM environment. Consider this scenario when running multiple non-redundant applications on a single server even with a cluster. When using VMware Distributed Resource Scheduler (DRS), we recommend creating rules to prevent VMotion from moving both servers to the same host, rack, and circuit where possible.
VMware introduced Fault Tolerance (FT) in vSphere 4.0.This feature creates a secondary copy of the virtual machine on a different host in the farm and replicates all instruction to this secondary machine.If the host of the FT enabled virtual machine fails, the secondary continues on as the host and a new clone is created.Fault tolerance can avoid a restart of a virtual machine if the physical host fails. However, it does not replace application level failover as the FT-created clone cannot be managed independently of the FT-enabled virtual machine (that is, a restart affects both).There are several requirements that must be met, including a limit to one virtual CPU (vCPU).If the virtual machine running PureConnect products requires more than one vCPU to meet the needs of your environment, this feature will not be available to it.
The Testing department has not yet performed an analysis of the FT feature.
Important!
We highly recommend that you first test the Fault Tolerance feature in
vSphere to ensure that it is meeting your expectations before moving it
forward to a production environment.